
 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
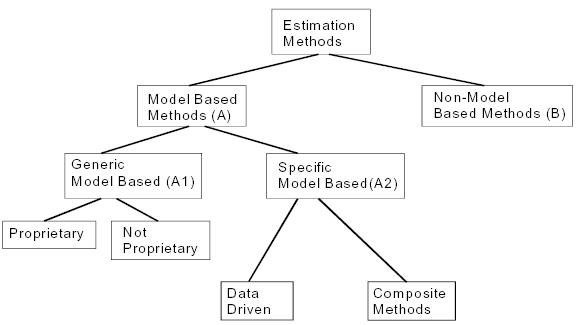
(click to enlarge the image) A recent paper (in Italian) at CNIPA by Prof. S.Morasca uses the same approach for his discussion. Another technical report proposing a different taxonomy is the one by Boehm, Abts & Chulani (Figure on p.4) Web Resources For each category, in the following there are some direct links to such resources:
Some thoughts about Generic Model-based Models Often Generic Model-Based models such as COCOMO and its variants are used and applied as-is, without taking into account the composition of the dataset on which such model has been built. For instance, COCOMO I was formulated using 63 projects while COCOMO II using 83 projects, most of which in COBOL, LISP and ADA programming languages. Many people speak about such models as "open" models. But they really seems to be "closed" models, in the sense that they propose a "black box" approach, where you apply your data to a dataset not necessarily having a good fit with your organization, the expertise of your project teams, programming languages, environments and all the proxies proposed by that model. So, what about the application of any model with a low fit your reality? Which level of predictability should be expected in return? In this case, a calibration of the basic values provided by the model should be done before applying it; here there are some papers about calibration on the Post-Architecture Model using also a Bayesian approach. Anyway, a lot of attention must be paid to this issue in order to obtain reliable estimated data. Some thoughts about Non-Model based Methods First of the two techniques/methods for this category is Expert Judgement. The lower part of the classification tree presented before reflects the opportunity to do not formalize the knowledge into models, even to use the experience by human experts case by case for estimating project. Well-known and recognized guides on Project Management such as the PMBOK (Project Management Body of Knowledge) in the "Estimate Activity Duration" process (process #6.3) proposes the "Expert Judgment" and the "Analogous Estimating" as the first two "tools & techniques" for satisfying that process. The "Quantitatively based durations" techniques are classified and treated after. This could be a simple but easy way to look at the relevance nowadays non-model based methods have in the estimation field, for several reasons. In particular, for the ICT sector there are several publications by Magne Jorgensen (Univ. of Oslo, Norway) looking at this aspects, with attention through statistical analysis to catch which could be the main drivers in human judgement for reducing estimation errors. This paper just published in the "IEEE Transaction on Software Engineering" provides an extensive review of studies related to expert estimation of software development effort, discussing why this kind of estimation should be better than using models. Another interesting paper by Passing & Strahringer, describing a process with three levels of prescriptiveness (Basic, Intermediate, Advanced)and two levels of decomposition (workflows and activities), based on the first two estimation criteria listed in the process #6.3 of the PMBOK2000. Second item classified here is the Delphi method. As discussed in this paper by Karl Wiegers, some flaws on the basic Delphi technique - not including team interaction among the experts composing the team were detected by Barry Boehm and his Rand colleagues, modifying it into the Wideband Delphi. A very quick summary on it is available in this presentation by Robert L.Galen (pages 3-7). A template for formalizing Wideband Delphi estimations is also available from one of the Carnegie Mellon University (CMU) courses. A starting point: applying Regression Analysis Due to the complexity in calibrating a database such as the COCOMO one and the several factors to manage, the starting point is a basic comprehension and usage of Statistics and Math also in Software Engineering, in particular of Regression Analysis, and its application your own projects database, where taking into account several qualitative factors, mainly organizational ones defining the project, such as: the project typology (New Development, Customization, Maintenance, ...), the Project Manager responsible for that project, the number of staff people involved in the project, the kind of Software Life Cycle selected (Waterfall, Spiral, ...) and its eventual approaches (Sashimi, eXtremeProgramming, SCRUM, Lightweight methodologies, ...): 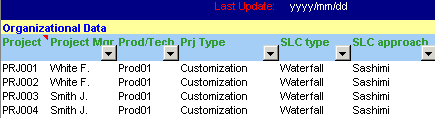 and quantitative data (at least - as said - the size, expressed preferreably with a FSM method unit, such as Function points, COSMIC fsu, ...) but also the effort distribution by SLC phase, the number of defects, and so on. It could be interesting, to accomplish with Sw-CMM requirements, to isolate the effort devoted for SQA and SCM activities (last two columns in next figure), since these activities should be performed by external groups. 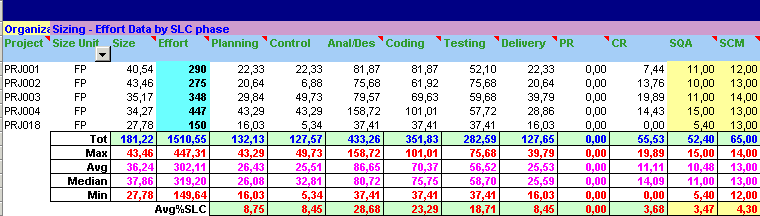
(click to enlarge the image) The application of the simple formulas for linear or exponential regression allows to obtain the two parameters for deriving the new project effort values. These are the formulas for linear regression: 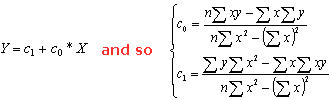 ) )and exponential regression:  , ,
and finally 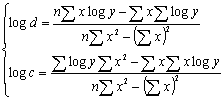
Click here for a simple MS Excel template based on these formulas. After the application of regression analysis, the total number of man/days for the new project will be derived on the base of the assumptions taken into account. Next step will be the distribution of effort by SLC phase. Thus, an interesting aspect to catch from the projects database should be the (re)calculation of some figures, as shown in last table (Max, Min, Avg, Median values plus the Avg% contribution that a certain phase within the whole project has given). For instance, considering those sample data, the Coding phase in the average takes 23.29% of the total effort, SQA activities only the 3.47% and so on. So, grouping projects by similarities (in a worksheet such this with Excel filters), it is possible to apply such figures on the new project or start from them in order to determine the new effort distribution. But what to do if there is no in place your own historical database available? Does it exist some study with a "standard" effort distribution? Capers Jones in a 2002 paper proposed a table with the list of the 25 most applied activities in Software Projects from 4 domains (Web, MIS, Systems and Military projects) for application of about 1000 FPs in size or larger. A 2001 paper reported on page 2 the SLC phase distribution on Rubin's data, even if the Code/Unit Test is a unique category. Another presentation from the Ottawa SPIN presents on slide 10 some standard figures (rules of thumb). Anyway, applying as-is those figures could be dangerous, since the application of a certain distribution - as said - should be done against projects with several similarities. Thus, a lot of attention must be paid to this aspects during the planning phase. Estimating with Incomplete Data A common and frequent problem could occur when building (or simply consulting) an historical project database for estimation purposes: some data could be incomplete and the most common practice is simply to ignore those observations. This practice (called listwise deletion) can lead to reduce the accuracy of cost estimation models. Several techniques have been therefore created - labelled under the MDT (Missing Data Techniques) acronym - to overcome this common situation with the aim to improve the accuracy in estimation. The most common ones are:
A reference publication is: Other papers referring/using MDTs are: Estimation studies by application domain It is possible to find several papers reporting experimental data applying estimation techniques or deriving formulas from data retrieved from the field, starting - for the MIS domain - from the one by Walston & Felix (1977) on the IBM Systems Journal, one of the first papers about this issue, and going on. Another good source with several papers on estimation from 1999 on is here. MIS projects This is the most treated domain, with several studies published. Here in the following there is a list of some valuable ones available online. Maintenance projects The most of the studies about Software Maintenance are from Netherlands. From the functional measurement side, NESMA (the Netherland Software Metrics Association), whose Counting Practice Manual is strongly devoted to count enhancement projects Web/Hypermedia projects Some particularities are be nowadays devoted to web/hypermedia projects. Holck & Clemmensen describe what should make web-development different from MIS applications, stressing that estimates cannot be based on functionalities. Reifer, taking note of such differences, proposes WebMo, an estimation model COCOMO-like for web projects, whose sizing method is Web Objects, based on the Function Point Analysis (FPA) method but considering in place of the traditional data/transaction elements (ILF, EIF, EI, EO, EQ) other "predictors" with a better fit with the web in addition to the traditional ones (# of xml-html-query lines, # of multimedia files, # of scripts, # of web building blocks). Software Estimation Tools Publications Cross References to this page
|
|